Hybrid PDFs: What’s next?
You can download the PDFs I refer to in this blog post.
In my last blog post I looked at a dozen ways to extract information from a PDF. A lot of you liked it, and I got suggestions for about a dozen more ways to extract information from PDFs. None of them is perfect, but each one is working well for the person who suggested it.
In this blog post I want to look at alternatives to brute-force extraction. It’s a feature that’s been part of PDFs for a long time, but never really taken off. I’m talking about Hybrid PDFs, and attached files.
Hybrid PDFs
In my PDF tests I showed how poor LibreOffice is at opening PDFs for editing. But I only hinted at the secret weapon it has to overcome this.
When you save a document from LibreOffice you have the option of creating a Hybrid PDF. That means that the original file is embedded in the PDF. If you open the PDF In Acrobat, or Chrome, or Edge or Preview on a Mac, you get a faithful reproduction of the original (that’s the PDF part). But if you open the file in LibreOffice, you get the original document, fully editable.
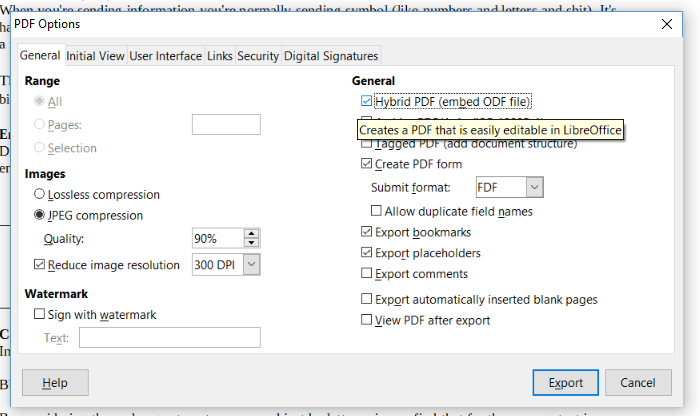
The problem with this is that even though ODF files are widely readable, LibreOffice the only piece of software I’ve found that knows what to do with the Hybrid PDFs it creates. Open them in Acrobat and there’s no indication that an ODF file is attached or embedded. There’s no indication in the metadata of the PDF, the file extension of a Hybrid PDF is the same as a normal PDF, and it’s surprisingly difficult to tell whether a PDF is hybrid in any automated way.
So Hybrid PDFs aren't really solving our problem. People don't know that they exist, few people use software that creates them, and it's very hard to even tell which PDFs are Hybrids.
Attached files in PDFs
I searched my computer and Microsoft Word created well over two-thirds of the PDFs that I have. Microsoft Word doesn’t support Hybrid PDFs. So what options are there here for making PDFs better at holding data?
One is to manually attach raw files to PDFs using Acrobat (or similar tools). Attaching files to PDFs is a well-documented feature and when you open a PDF with attached files in the free Acrobat Reader they show up in a tab on the left, making them more discoverable than Hybrid PDFs.
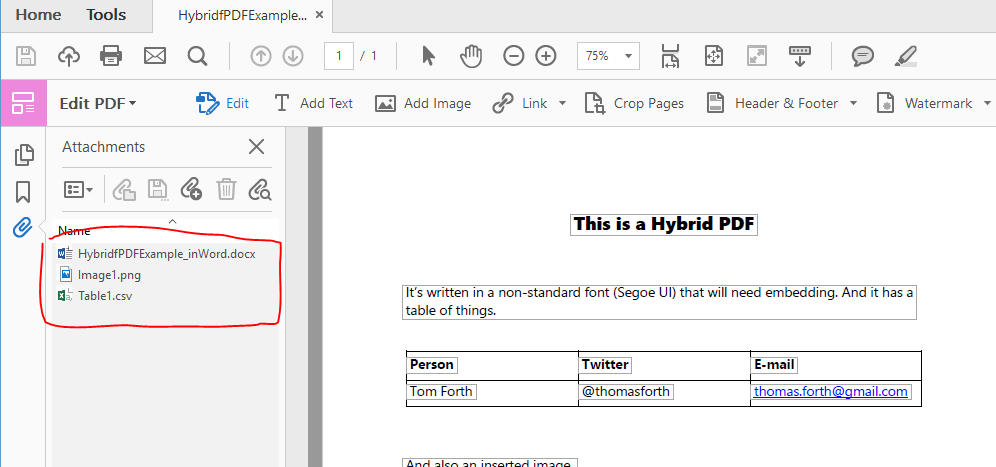
But adding the files requires Acrobat Pro and when you open a PDF in other readers, like Preview on the Mac, or in browsers like Chrome or Edge you won’t see any clue that there are attached files.
In the example I’ve shown I’ve done some interesting stuff – I’ve embedded the original file so an editable copy is archived along with the PDF, and I’ve embedded the image and the table of data so they can be read and re-used in full confidence and at full quality.
But we’ve still got the problem that few people know that hybrid PDFs and file embedding exists. There aren’t good ways to signpost that a PDF contains files. We need to do better.
What’s next? Beyond hybrid and attachments
Recently I wrote about the work we’re doing with The Future Cities Catapult on helping to inform planning opinions and decisions with data . At the end I teased what I think might be the solution to this problem. We call if PDFs for Planners at the moment.
So here’s a second look. The output from A Clearer Plan is a document, but with the data that created it embedded in a machine-readable way. It has links back to the tool that created, so you can always look at the latest data. And it’s also editable, so that opinions can be added without changing the underlying data.
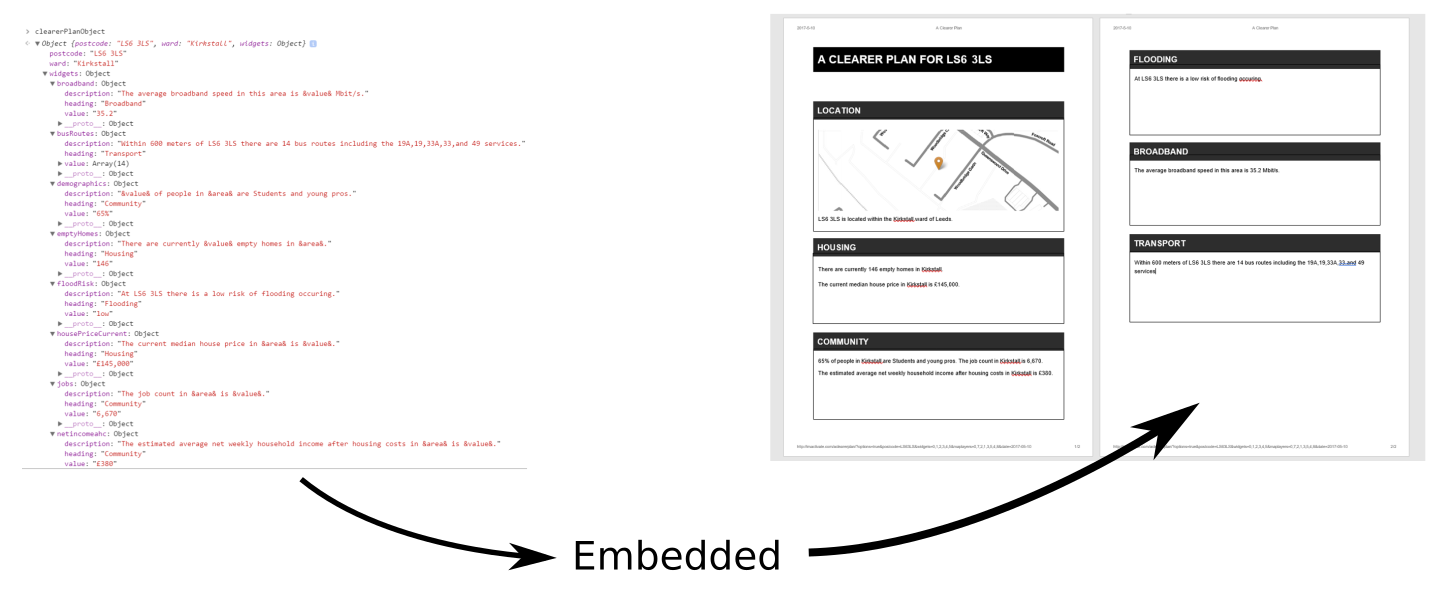
But there’s still a big problem with what we’ve built, and that’s that no-one opening the PDF, or editing the Word document, knows that there’s data embedded in it.
So in my next blog I’ll explain more about PDF for Planners, and what we’ve built to fix that discoverability problem.
If you’ve done something similar and already fixed the problems I’ve described then I’d love to hear from you. Comments are open below, or join our W3C community group , or find me on twitter or email.